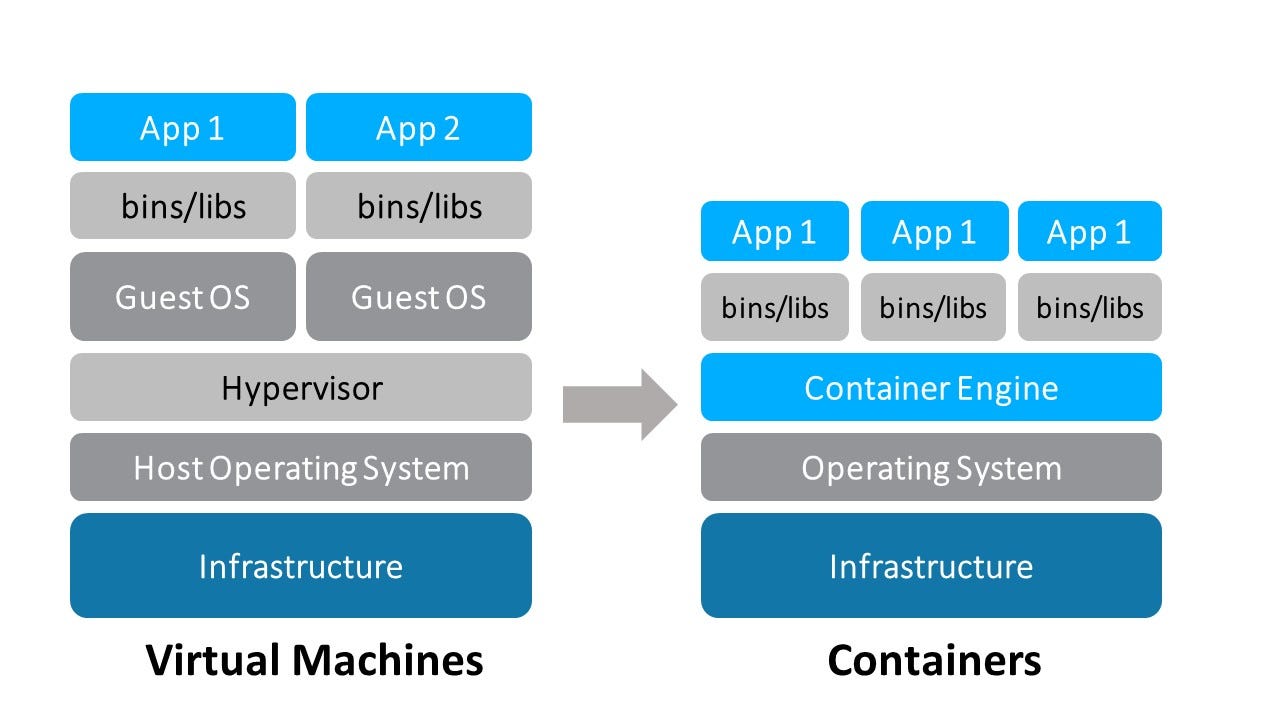
Docker vs VM:
how to run containers from prebuilt, publicly available Docker Image
docker-machine env default
eval $(docker-machine env default)
Docker: ` docker run –rm -p 40:8888 jupyter/scipy-notebook
+ -p <host_port>:<container_port>
Host Browser: docker-machine ip:40`
“ssh” Into Running Containers
docker ps in a separate terminal to get containiner ID
docker exec -ti <container id> bash
build custom (python) images by writing a Dockerfile
see https://mlinproduction.com/docker-for-ml-part-2/
write a dockerfile, then something like docker build --build-arg SOME_ENV_VAR=hello -t my-jupyter-image -f Dockerfile .
How to run containers from this image - i.e., running custom Docker Image
docker run --rm -p 8888:8888 my-jupyter-image
How to use Volumes to persist data in containers
By default, files created inside a container do not persist when the container exits. One simple way to persist data past the lifecycle of a container is to use volumes. You can think of a volume as a file system mount that allows Docker to access and persist data to the filesystem of the host machine.
docker run --rm -p 8888:8888 -v <local path>:/home/jovyan/work my-jupyter-image
- where -v HOST_PATH:CONTAINER_PATH
how to set up a model training pipeline in a Docker container and how to use the images we build (run the container) for inference - make predictions
Training and serializing a model during the image build process and performing inference in a running container. Specifically, we will embed the trained model into the Docker image (i.e., save the files in the image). Then, whenever we want to run inference, we simply need to run a container from that image, deserialize the model, and generate our predictions.
It also allows us to use a container registry service, like Amazon’s Elastic Container Registry (ECR, ECS). Rather than worry about persisting individual model components, we can just store entire Docker images (if we train as we build the image) which contain all of the necessary model artifacts.
- see /Users/dleung/Hack/packaging/Dockerize for example
A model that is used to generate a batch of predictions on a recurring schedule doesn’t need to be served as an API (although it could be). This is called batch inference (offline).
For example, lets say your company has built a lead scoring model to predict whether new prospective customers will buy your product or service. The marketing team would like to predict whether individual leads will convert, but they don’t necessarily need the predictions right away. Instead, they’re happy so long as new leads are scored within 24 hours of entering the system. Rather than performing inference as leads enter our system, we can perform inference each night on the batch of leads generated that day. This will guarantee that all leads from the previous day are scored within the agreed upon time frame.
Model is typically retrained when new training data is available (e.g., every few months or maybe more frequently), and batch inference (make new predictions based on new unseen data) is performed weekly.
Real time inference / dynamic inference (online)
Generate ML predictions in real time upon request, by exposing a trained model through a REST API (e.g., Flask-RESTful). REST stands for representational state transfer.
- e.g., UberEats, recommendation based on web response/input
remove Docker image
docker ps
docker images -a
docker rmi <imageID>
https://stackoverflow.com/questions/38118791/can-t-delete-docker-image-with-dependent-child-images