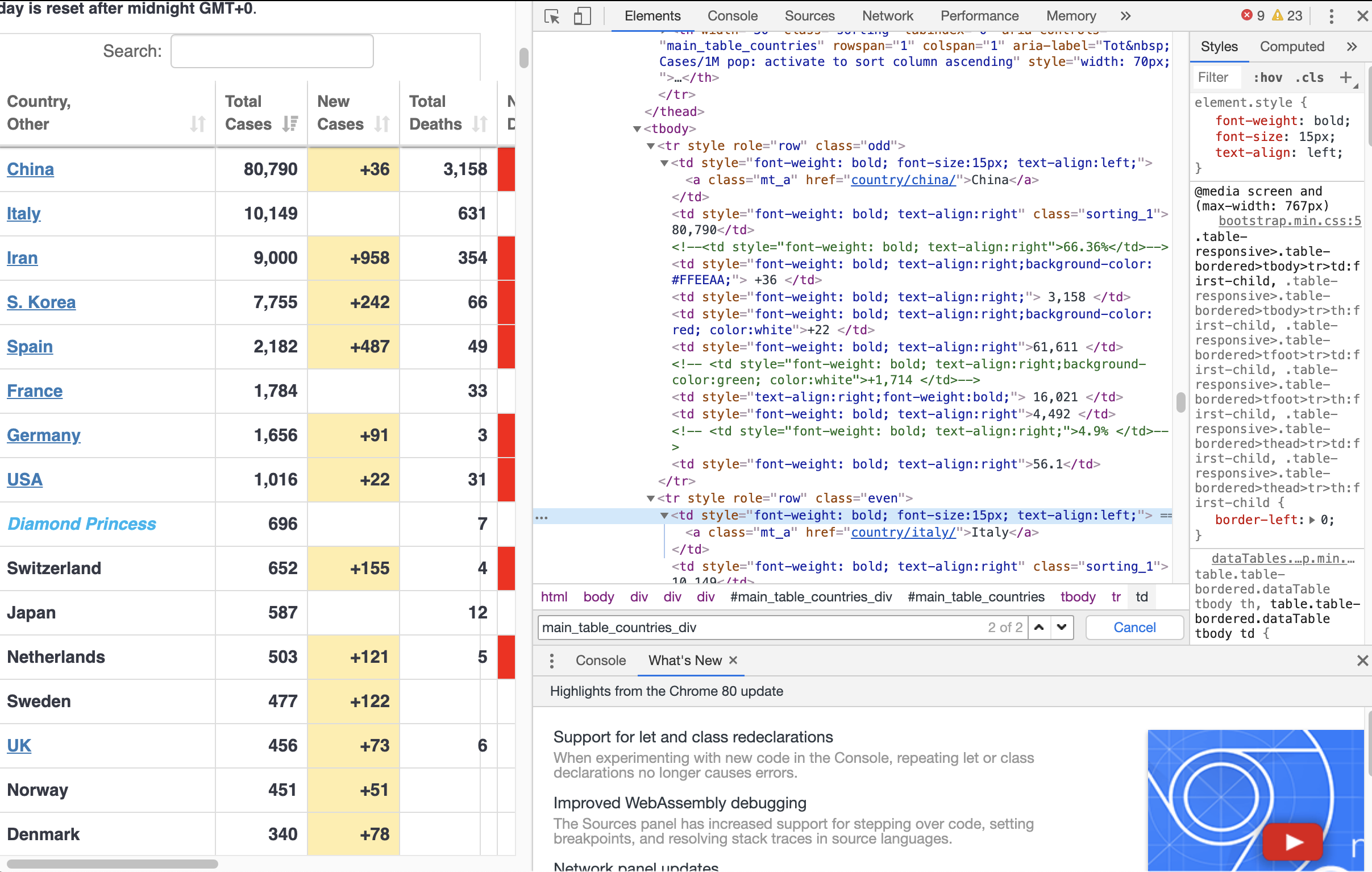
My (second?) time webscraping. This time I am not scraping my own facebook data, instead, I webscrapped some numbers regarding the number of coronavirus from across the world.
Since the page I webscrapped provides a table with some of these numbers, the code for webscrapping is quite straightforward. On the other hand, I practiced writing codes for data cleaning and formatting unstructured data. In particular, some entries for some rows in the table are missing.
I use selenium and chromedriver to do the webscraping.

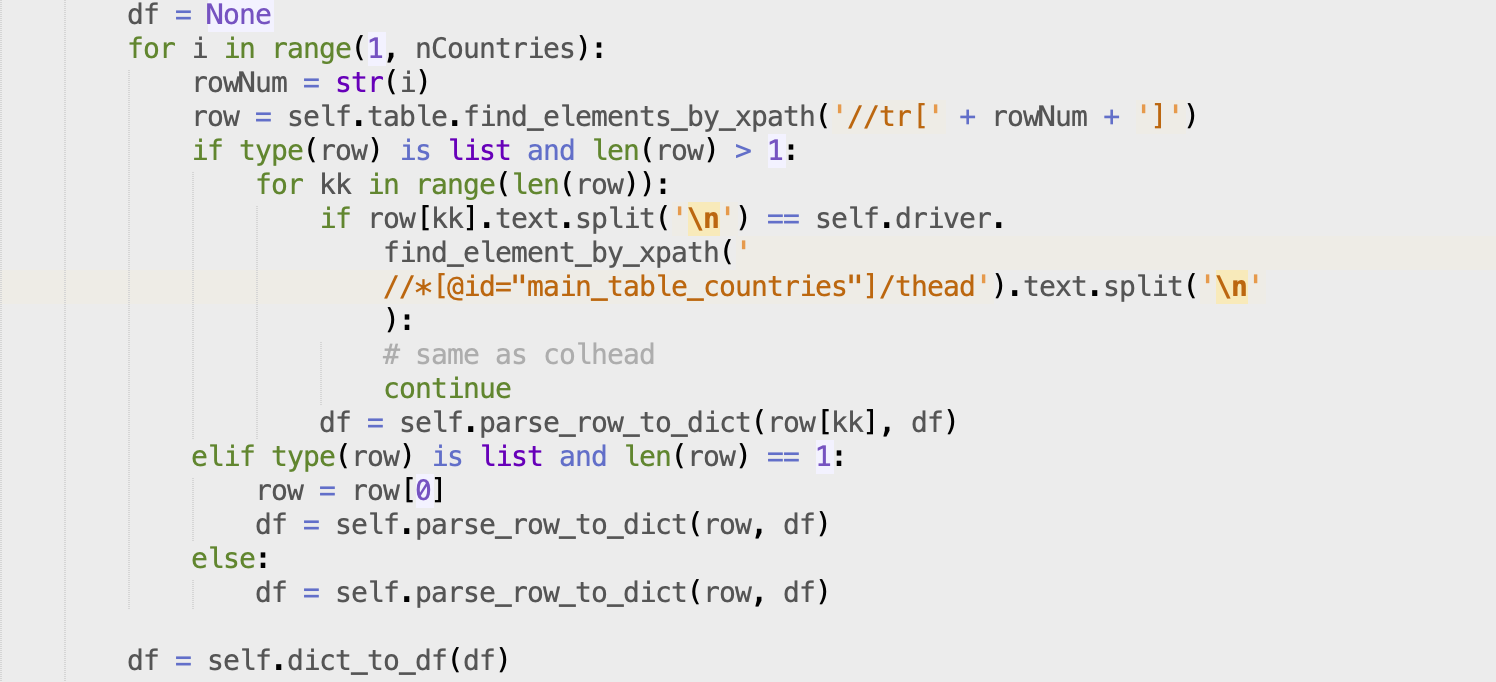
To deal with country names that are splited into multiple elements of a list after scraping each row of the table:

European standard uses ‘,’ for thousands, etc. To convert numbers into floating point, I need to first remove ‘,’ from the entry stored as a string. Since there are missing entries in the table, we want to replace it with something that we could convert into a floating point number, since the rest of the columns (except for country name) should and will become a float in the final dataframe. In Astronomy, it’s common that if a number is missing, or a measurement is an upper or lower limit, ‘-99’ is used. I adapted such convension into my webscraping/data engineering step.

To get the data for all the countries, I wrote a loop and calls a method within that class parse_row_to_dict() to get the data for a given country, and put that dictionary df into a pandas dataframe.
After getting the datafrmae, I save the dataframe based on the time and date. The idea is to automate this webscraping and save the dataframe periodically.

Finally, I use cron to webscrape every 6 hours by executing the python script. In particular, I added 0 0,6,12,18 * * * /anaconda2/bin/python corona.py to my cron job list.
